
 Artikel ini akan menjelaskan alat ini yang tidak hanya dapat memberikan wawasan yang berharga, tetapi juga memfasilitasi pengambilan keputusan, memantau tren pasar, dan banyak lagi, menjadikan web scraping sebagai alat yang sangat kuat dalam dunia berbasis data.
Artikel ini akan menjelaskan alat ini yang tidak hanya dapat memberikan wawasan yang berharga, tetapi juga memfasilitasi pengambilan keputusan, memantau tren pasar, dan banyak lagi, menjadikan web scraping sebagai alat yang sangat kuat dalam dunia berbasis data.
Apa Itu Web Scraping?
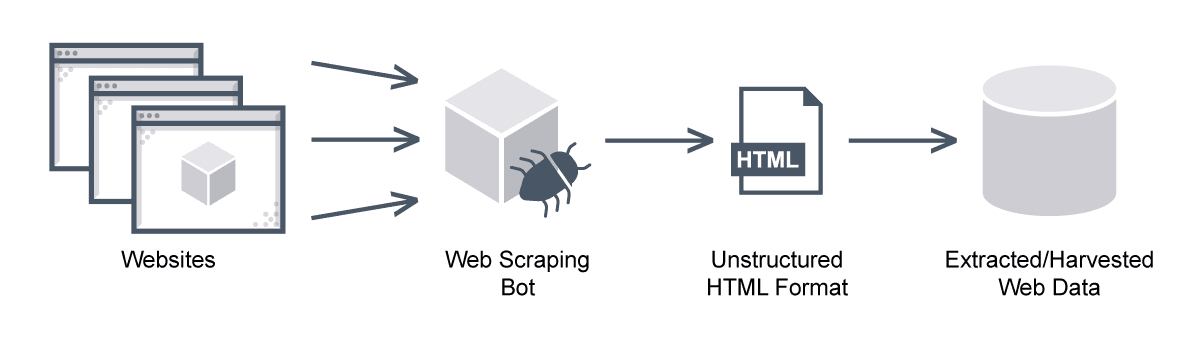
Web scraping adalah teknik untuk mengekstraksi informasi dari situs web dengan membuat permintaan HTTP ke URL tertentu dan mengekstrak data dari kode HTML yang diterima sebagai respons. Data yang diekstraksi kemudian dapat disimpan di komputer lokal atau server jarak jauh. Web scraping digunakan untuk mengumpulkan data untuk berbagai keperluan, seperti penelitian, pengembangan, atau untuk mengekstrak informasi spesifik seperti alamat email, harga barang, ulasan, dan lain-lain. Namun, perlu diingat bahwa web scraping harus dilakukan dengan tanggung jawab, mematuhi file robots.txt situs web, serta pedoman hukum terkait privasi data dan hak cipta.Legalitas Web Scraping
Meskipun tidak ada undang-undang yang secara eksplisit membuat web scraping ilegal dalam semua situasi, praktik ini dapat menjadi kontroversial secara hukum jika melanggar privasi, persyaratan layanan, atau undang-undang hak cipta. Legalitas web scraping sangat bergantung pada beberapa faktor, seperti jenis data yang di-scraping, metode yang digunakan, kebijakan privasi situs, dan undang-undang privasi dan hak cipta yang berlaku di berbagai negara.Tantangan Web Scraping
Web scraping menghadapi sejumlah tantangan, antara lain:- Keanekaragaman dan kompleksitas situs web: Situs web memiliki berbagai desain dan struktur, beberapa di antaranya menggunakan JavaScript untuk memuat konten secara dinamis, sehingga sulit untuk diekstraksi oleh web scraper sederhana.
- Menangani volume data yang besar: Memproses dan menyimpan data yang diekstraksi dalam jumlah besar memerlukan sistem yang kuat, terutama untuk ekstraksi data secara real-time.
- Masalah privasi dan hukum: Menghormati file robots.txt dan peraturan privasi data penting untuk menghindari masalah hukum. Selain itu, banyak situs web menggunakan teknik anti-scraping seperti CAPTCHA dan pemblokiran IP.
- Pemeliharaan dan pembaruan: Situs web sering mengubah strukturnya, sehingga kode scraper harus dipantau dan disesuaikan secara teratur.
- Teknologi Anti-Scraping: Situs web juga dapat menggunakan teknologi khusus untuk mendeteksi dan memblokir web scraper, seperti menganalisis pola permintaan dan mengimplementasikan honeypots.
Cloudflare sebagai Teknologi Anti-Scraping
Salah satu teknologi yang digunakan untuk mendeteksi web scraper adalah Cloudflare, sebuah jaringan pengiriman konten (CDN) yang populer. Cloudflare melindungi situs web dengan mengidentifikasi dan memblokir aktivitas mencurigakan, termasuk upaya web scraping, menggunakan berbagai teknik seperti tantangan JavaScript, CAPTCHA, dan pembatasan kecepatan IP. Untuk berhasil melewati Cloudflare dan mengekstrak data dari situs web, scraper perlu mempertimbangkan strategi seperti:- Merekayasa balik teknik pendeteksian Cloudflare dengan meningkatkan pertahanan menggunakan koneksi HTTP2 dan JavaScript yang umum digunakan.
- Menggunakan browser web sebenarnya sebagai alat untuk web scraping, seperti Selenium, Playwright, atau Puppeteer.
- Mengatasi jejak yang ditinggalkan oleh alat otomatisasi dengan menggunakan plugin atau ekstensi siluman.
- Menggunakan browser dengan profil sidik jari yang berbeda untuk meningkatkan keberhasilan dalam melewati Cloudflare.
Kontributor: Syauqi Wiryahasana
Model: Haifa Manik Intani
